New Features in Liquibase Linter 0.3.0
Liquibase Linter 0.3.0 is released and available now in Maven Central!
In this release we have fixed a few issues, but primarily we've been restructuring the codebase and adding new features including improved logging and custom rules support.
New core rules
- The new
no-schema-namerule will prevent changes that use theschemaNameattribute. This supports the practise we follow internally, where we run Liquibase once per schema with a user who only has access to that schema.
JSON and YAML support
You can now use Liquibase Linter with scripts written in JSON or YAML, as well as XML.
Console reporting and fail-fast
Previously, we would exit the Liquibase process as soon as the first rule failed. This was not ideal if there were several script issues, as you would need to fix each one in order to find the next --- this made it especially tedious to try to retrofit the linter to an existing project.
Now, we allow all changes to be checked, collecting failures as we go and reporting them in a readable way in the console at the end:
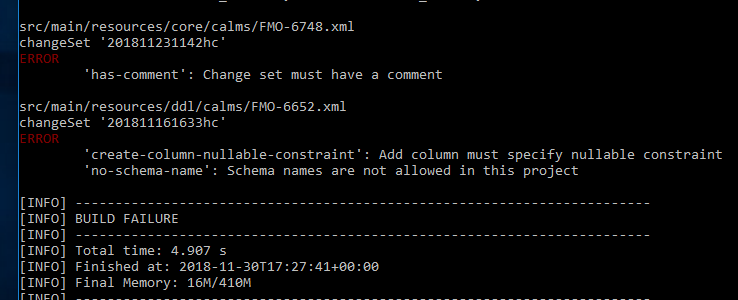
(Note that we still don't allow any script to be run if there is a failure; the linter hooks into the parsing phase of Liquibase's lifecycle, and with failures we force the process to exit before it even starts generating SQL.)
Custom rules
You can now write your own rule that's specific to your project or company and use it in Liquibase Linter. There's a complete guide in the docs, but essentially you just need to write a Java class and do a little configuration in your project.
This is the change we're most excited about, as it will give users the power to extend the linter to solve their own particular problems with relative ease.
In support of this, we've also refactored the codebase quite heavily so that all of our core rules are implemented using the same mechanism as custom rules, so any additional power that gets added to rules in future will benefit both.
Next
Here are some things we've got lined up for the next couple of releases:
- Improving the core suite of rules
- Support for running with Gradle
- Flexible reporting e.g. JUnit, HTML